
面试问题汇总
AE
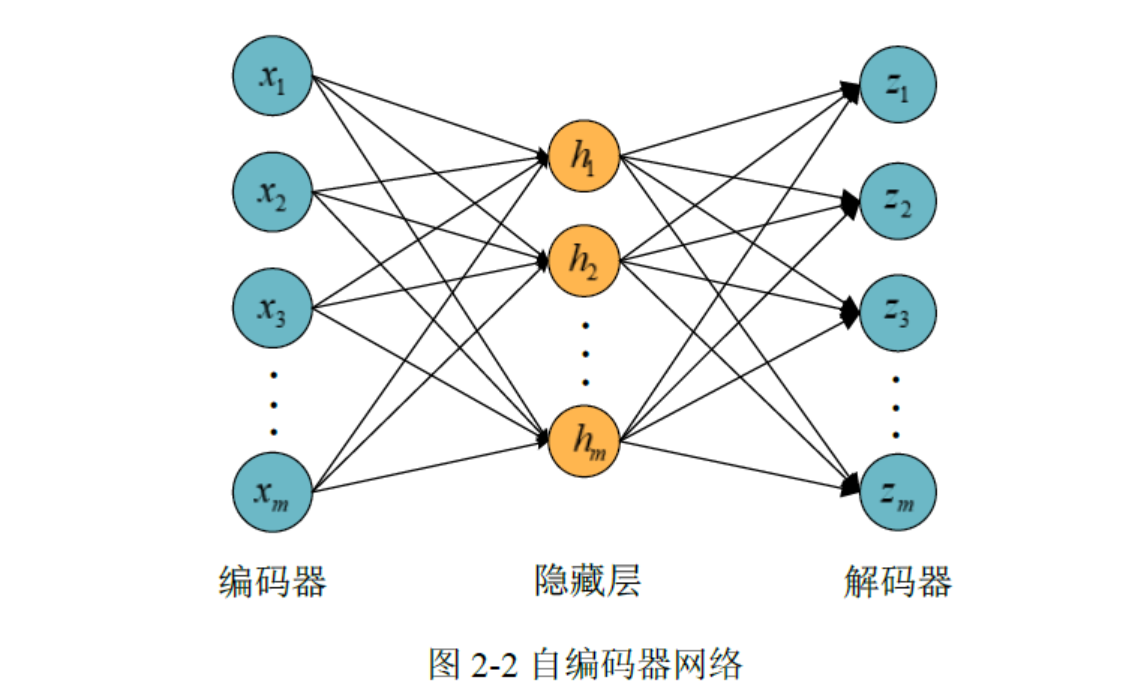
AE的Pytorch代码实现(MINIST数据集)
1 | import torch |
VAE
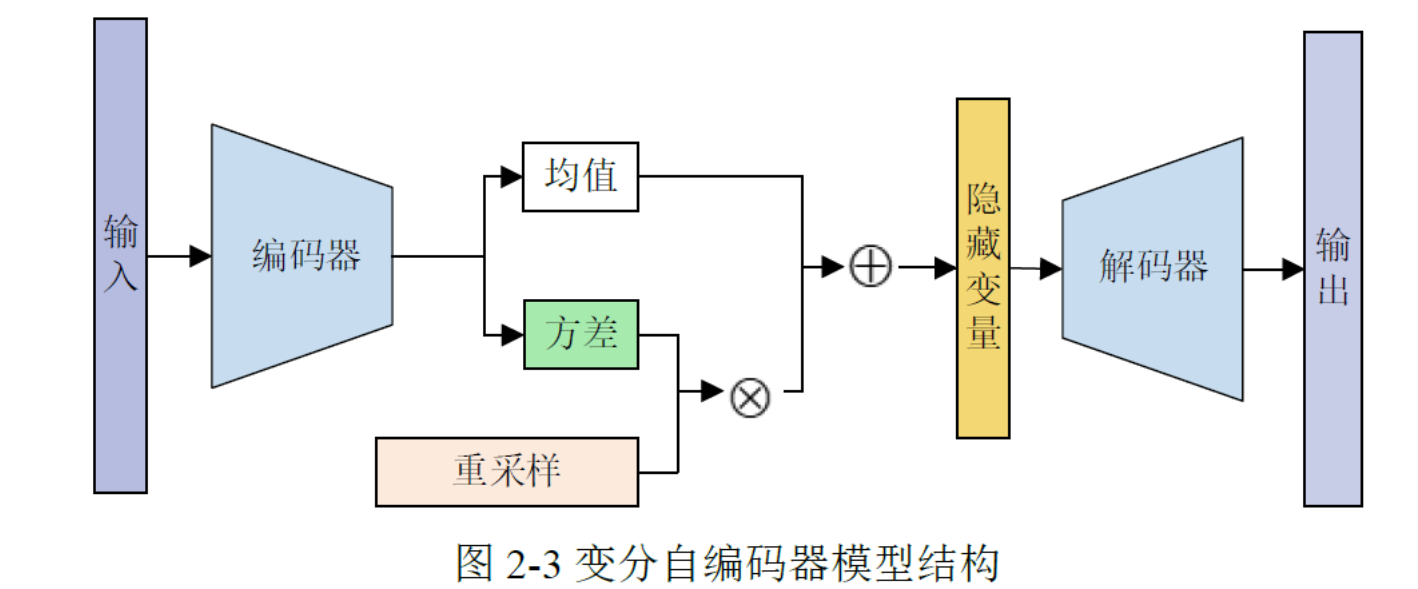
VAE的Pytorch代码实现(MINIST数据集)
1 | import torch |
1.VAE损失函数构成

损失函数通常采用交叉熵损失函数。
2.VAE的重参数化

GAN
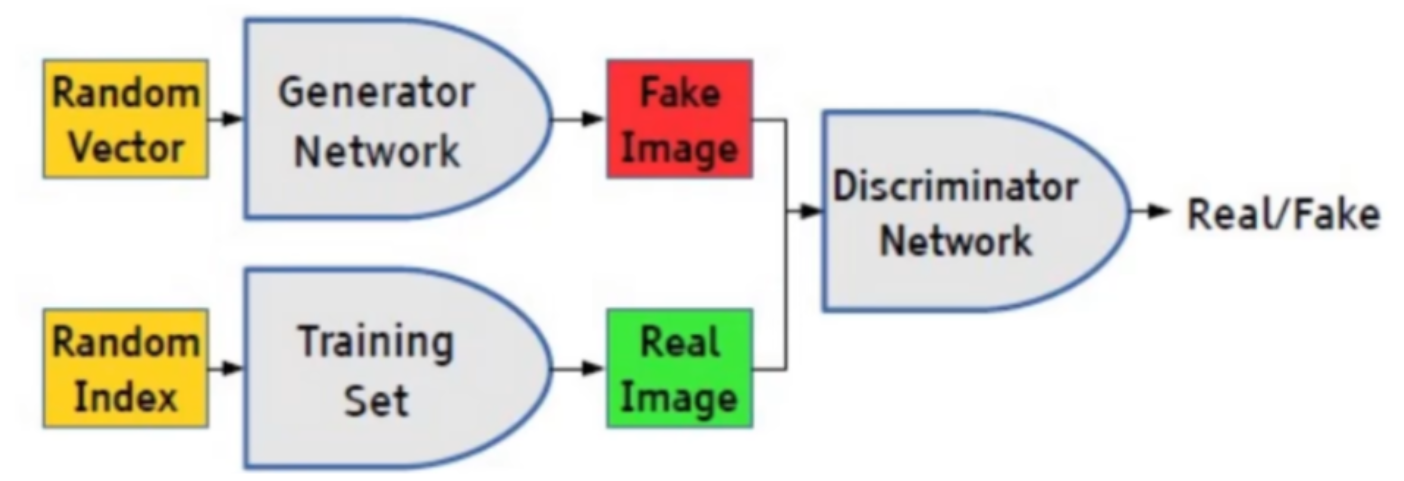
GAN的Pytorch代码实现
1 | import torch |
1.GAN损失函数构成
GAN的损失函数由两部分组成:生成器(Generator)的损失函数和判别器(Discriminator)的损失函数。生成器的损失函数旨在使生成的样本尽可能地接近真实样本,而判别器的损失函数则旨在正确区分真实样本和生成样本。
生成器的损失函数通常使用生成样本被误认为真实样本的概率来衡量,目标是最大化这个概率,使生成的样本更接近真实样本。判别器的损失函数则包括将真实样本正确分类为真实样本的概率和将生成样本正确分类为生成样本的概率,目标是最小化这两个概率之和,使判别器能够准确地区分真实样本和生成样本。
一般来说,GAN的损失函数可以表示为生成器和判别器损失函数之和的形式。两种损失一正一负,他们的和越趋近于0性能越好。一般生成器的损失函数是负值,判别器的损失函数是正值,最终要最大化生成器损失最小化判别器损失。
损失函数通常采用交叉熵损失函数。
U-Net
U-Net是一种用于图像分割的深度学习架构,由Ronneberger等人于2015年提出。它的名字源自其U形状的网络结构。U-Net结合了卷积神经网络(CNN)的编码器和解码器结构,以实现精确的图像分割。其主要特点包括对称的编码器和解码器路径,跳跃连接以保留更多低级别特征信息,以及使用反卷积操作进行上采样。这使得U-Net在医学图像分割等领域取得了很好的效果,因为它能够准确地提取图像中的目标并保留细节信息。
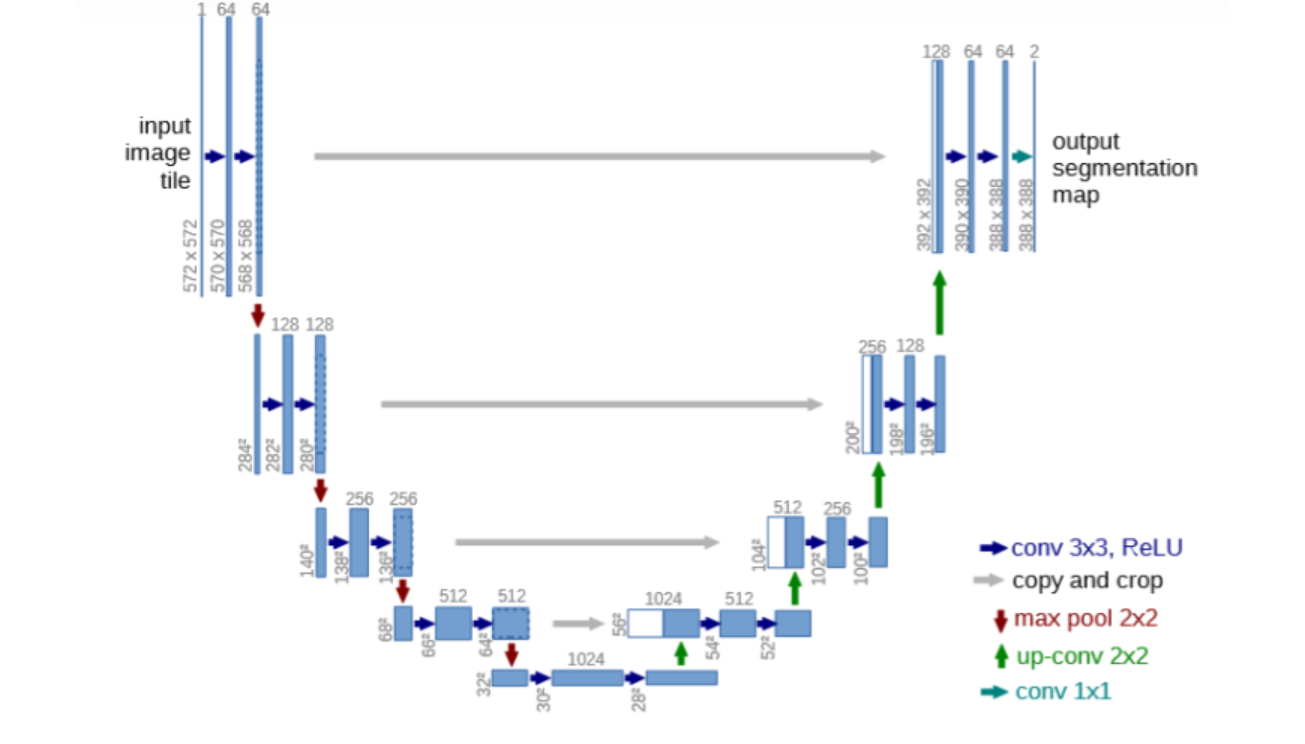
U-Net的Pytorch代码实现
1 | import torch |
1.U-Net与VAE都是编码器解码器结构,它们有什么区别
VAE和 U-Net 有几个显著的区别:
- 任务类型:
- VAE 通常用于生成模型,旨在学习数据的潜在表示,并生成与输入数据相似的新样本。
- U-Net 主要用于图像分割任务,其目标是从输入图像中预测像素级别的标签。
- 结构设计:
- VAE 通常由编码器和解码器组成,编码器将输入数据映射到潜在空间中的分布参数,解码器将潜在表示重新映射回数据空间。
- U-Net 结构通常由对称的编码器和解码器组成,其中编码器用于提取图像的特征,解码器则用于将特征映射回输入图像的相同尺寸。
- 应用领域:
- VAE 适用于生成各种类型的数据,如图像、文本等,它可以用于图像生成、图像重建、图像去噪等任务。
- U-Net 主要用于图像分割任务,如医学图像分割、卫星图像分割等领域。
虽然 VAE 和 U-Net 都是深度学习模型,但它们的设计和应用场景有很大的区别,因此不能将它们视为同一类模型。
Transformer
Transformer的Pytorch代码实现
1 | import torch |
面试问题汇总(杂)
1.过拟合怎么解决
dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。dropout为什么能防止过拟合,可以通过以下几个方面来解释:
- 它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
- 类似于bagging的集成效果
- 对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。 比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次dropout其实都相当于增加了样本。
dropout在测试时,并不会随机丢弃神经元,而是使用全部所有的神经元,同时,所有的权重值都乘上1-p,p代表的是随机失活率。
L1和L2正则化
L1正则化和L2正则化的主要区别在于它们对权重的惩罚方式不同。L1正则化倾向于产生稀疏权重,即使很多权重趋向于零,而L2正则化倾向于使权重分散在各个特征上,但不会将它们变为零。
增加数据(数据增强)
大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 红线也会慢慢被拉直, 变得没那么扭曲 .
从数据源头获得更多数据:多拍点照片等。
数据增强(data augmentation):通过一定规则来扩充数据,比如旋转,平移,亮度,切割等手段一张图片得到多张。
提前停止(Early stopping)
它通过在训练过程中监控验证集上的性能,并在性能开始下降时停止训练,来防止模型过度拟合训练数据。这种方法有效地控制了模型的复杂度,使其不会在训练数据上过分拟合,从而提高了模型的泛化能力。
2.BN和LN
BN 和 LN 都是用来解决神经网络中的梯度消失和爆炸问题的方法。BN(批量归一化)是在每一层的输入上进行归一化,而 LN(层归一化)是在每个样本的输入上进行归一化。它们的作用都是将输入数据进行归一化处理,有助于加速训练过程并提高模型的泛化能力。
区别
BN(批量归一化)和LN(层归一化)在神经网络中都是用来解决梯度消失和梯度爆炸问题的方法,但它们之间有一些区别:
- 作用对象:BN是在每一层的输入上进行归一化,即对每层的输出进行归一化处理;而LN是在每个样本的输入上进行归一化,即对每个样本的输出进行归一化处理。
- 归一化方式:BN是对每一层的输出进行归一化,通过计算每个特征在整个批次上的均值和方差来实现归一化;而LN是对每个样本的输出进行归一化,通过计算每个样本在所有特征上的均值和方差来实现归一化。
- 应用场景:BN通常应用于深层神经网络中,可以加速训练过程并提高模型的泛化能力;而LN通常应用于循环神经网络(RNN)等结构中,可以提高模型对序列数据的建模能力。
总体来说,BN和LN都是用来解决梯度消失和梯度爆炸问题的有效方法,但在具体应用时需要根据网络结构和任务特点选择合适的归一化方法。
3.介绍注意力机制
注意力机制是一种用于增强神经网络性能的技术,它模拟人类注意力的行为,使网络能够在处理输入数据时更加关注重要的部分。在注意力机制中,网络学会了动态地分配不同权重给输入的不同部分,以便更好地处理信息。
具体来说,注意力机制通常包括三个关键组件:
- 查询(Query): 查询是用来获取对输入的关注程度的向量。它可以看作是网络要查询的信息。
- 键(Key)和值(Value): 键和值是与输入数据相关联的向量。键向量用于计算注意力权重,而值向量则是要被加权的输入数据。
- 注意力权重(Attention Weights): 注意力权重是由查询和键计算得到的权重向量,用来指示网络对值的关注程度。这些权重确定了输入中每个部分对最终输出的影响程度。
通过计算查询与键之间的相似度,然后将相似度转换为注意力权重,注意力机制能够使网络在处理输入数据时自动地学习到哪些部分是最重要的。这种机制已被成功地应用于各种任务,如机器翻译、图像标注和自然语言处理等领域,取得了显著的性能提升。

