
LORA的相关原理及训练
LORA的相关原理及训练
随着AIGC的相关技术发展,人们热衷于将自己喜欢的概念或角色通过模型微调融入进作品里。但传统的Dreambooth方法对配置要求很高,同时TI、Hypernet等轻量级手段又没有那么好用。
这时有人发现了一个早在之前微软开发出来用于GPT-3的模型优化技术,它可以在保证质量的同时将模型训练参数量减少10000倍,同时还能让显存需求降到原来的三分之一,于是便想将它应用到扩散模型。随后这项技术被开源到网上,并被称为“低秩适应模型(LoRA)”。
LORA的原理
随着 ChatGPT 的爆火,很多机构都开源了自己的大模型,比如清华的 ChatGLM-6B/ChatGLM-10B/ChatGLM-130B,HuggingFace 的 BLOOM-176B,OpenAI 的 ChatGPT/GPT-4,百度的文心一言,谷歌的 PLAM-540B,华为的盘古大模型,阿里的通义千问,等等。
但是,对于大模型的微调训练是需要耗费很大的资金的,比如ChatGPT这种大模型,训练一次成本就在上千亿美元。那么有没有低成本方法微调大模型呢?
目前主要有Adapter Tuning,微软提出的LORA,斯坦福提出的Prefix-Tuning谷歌提出的Prompt Tuning以及清华提出的P-tuning v2。
这些方法各自存在一些问题:
Adapter Tuning 增加了模型层数,引入了额外的推理延迟
Prefix-Tuning 难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
P-tuning v2 很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差。
这时有人发现了一个早在之前微软开发出来用于GPT-3的模型优化技术,它可以在保证质量的同时将模型训练参数量减少10000倍,同时还能让显存需求降到原来的三分之一,于是便想将它应用到扩散模型。随后这项技术被开源到网上,并被称为“低秩适应模型(LoRA)”。
LORA的原理
之前在Stable Diffusion的工作原理中有提到,SD模型的工作核心就是文本编码器(Text Encoder)与噪声预测器(Noise Predictor)。文本编码器只负责将文本提示转换为嵌入向量,但实际上大部分通过扩散生成图像的工作还是由后面的噪声预测器完成。
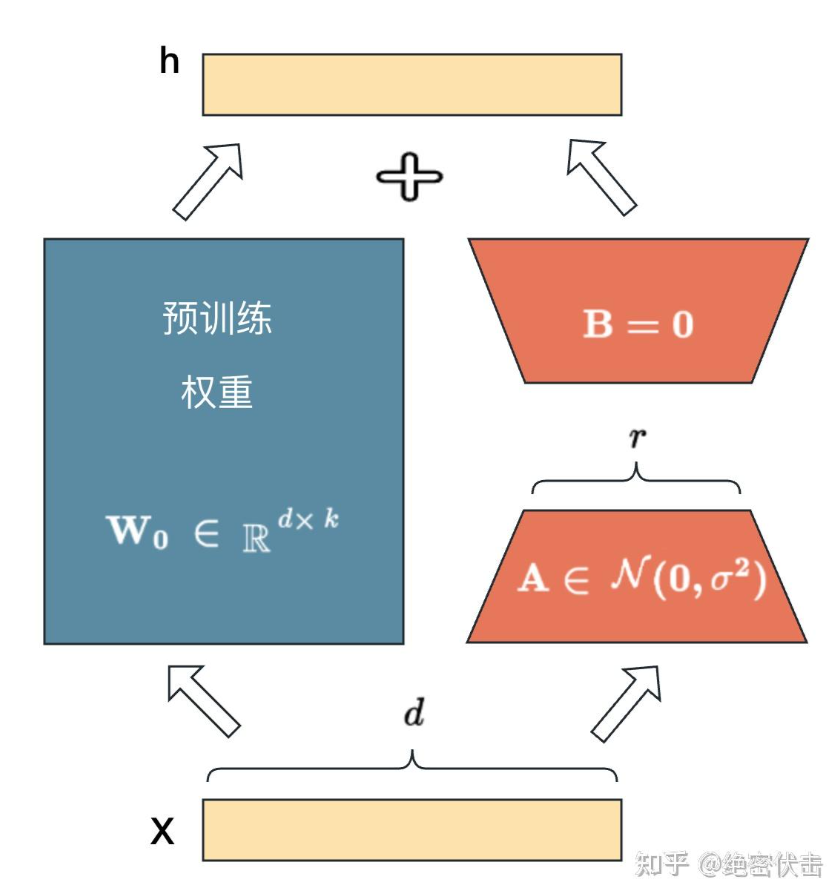
Textual Inversion就是只微调了文本编码器,将输入图像的生成方式与用户创建的新的“嵌入向量”产生关联,其工作中心在文本编码器阶段,在这个过程中噪声预测器(U-Net)的工作方式是没有发生变化的,因而效果没有那么好。而诸如Dreambooth等手段则会将这两个部分一起微调,但噪声训练器训练起来比文本编码器难得多。Dreambooth(Native Fine-tune)的高配置需求就是为了能够同时去微调这里面的所有参数。在网络中控制模型算法运行逻辑的是模型权重,在复杂的网络中各种权重以矩阵的形式储存在一起。LORA做的事情主要是“冻结”了原始模型的权重,在旁边另起了一个单独的“微调权重”来进行训练,同时在这个微调权重部分进行了“偷工减料”,他们采用的方式是计算权重矩阵时只计算开头的2行2列,调出来的模型在处理任务时表现和微调1000行1000列其实差不多。所以LORA创建了两个额外的“转换器”,一个把原始参数从”满秩“状态转换为”低秩“,另一个又将“低秩”参数转换回“满秩”,我们就只需要让模型学习这两个“小矩阵“里的数据变化就可以了,这就是它实现大幅度”降本增效“的方式,从而使得”炼模型”的成本大大降低。
LORA训练
为了便利性,许多开发者开发出了相关的训练脚本,其中使用最广的一套训练脚本便是Kohya,后续也出了相关的UI界面,不仅可以训练LORA,还能训练Dreambooth、TI或进行直接微调。
LORA的训练流程主要分为三步:
1.收集训练集,收集到的训练集图片应尽量涵盖训练对象的”多样化样本“,比如角色立绘图、以及各个不同角度的角色建模截图以及二创作品等等,对于单个人物训练图片选取二十到三十张即可。
2.图片与处理(裁剪+打标),裁剪使用WebUI预训练(后期处理)的只能裁剪即可,裁剪完可以手工对不好的图片重新裁剪。对于打标,可以使用WebUI后期处理中的BLIP和DeepBooru或者用WD1.4Tagger插件。
3.模型训练,涉及到一些超参数与优化器的设置,这里不多赘述。

