
stable diffusion
Stable Diffusion原理
生成式人工智能内容(AIGC,Artificial Intelligence Generated Content)是指由人工智能系统生成的各种形式的内容,包括但不限于文字、图像、音频和视频等。这些内容是通过训练好的深度学习模型生成的,这些模型可以根据输入的条件或上下文生成新的内容。
在生成式人工智能内容中,语言模型如GPT(Generative Pre-trained Transformer)系列等可以生成各种类型的文本,包括文章、故事、诗歌等。图像生成模型如GAN(Generative Adversarial Networks)可以生成逼真的图像,甚至可以用于图像修复、风格转换等任务。类似地,音频和视频生成模型也在不断发展,能够生成逼真的声音和视频片段。
生成式人工智能内容在许多领域都有应用,包括创意内容生成、教育、娱乐、广告等。然而,尽管这些技术有着巨大的潜力,但也引发了一些问题,如内容的真实性、道德问题和版权问题等,需要在使用和发展过程中加以关注和解决。
Stable Diffusion是现在常用的一种技术,用于AI绘画,本期内容将对stable diffusion的原理进行一波解释。参考秋叶aaaki
Stable Diffusion模型整体上是一个End-to-End模型,主要由VAE(变分自编码器,Variational Auto-Encoder),U-Net以及CLIP Text Encoder三个核心组件构成。
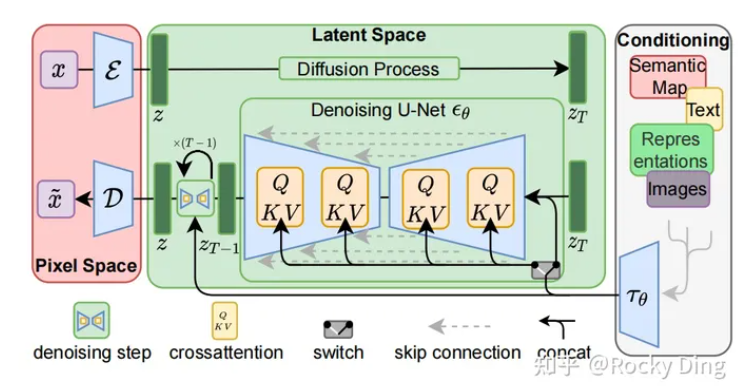
结构概括一下如下图所示:
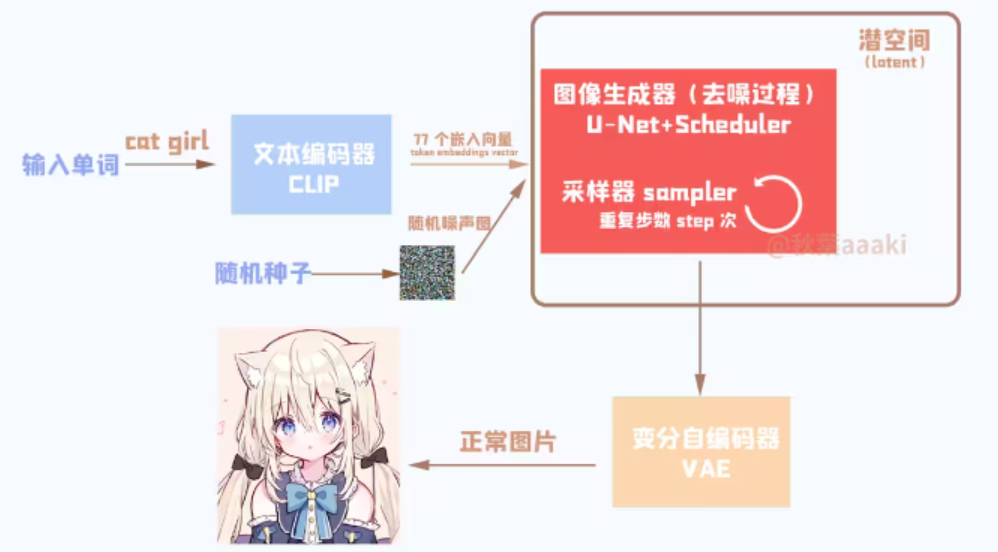
首先将输入的单词送入文本编码器CLIP得到嵌入向量,然后送入U-Net,生成图片后送入VAE生成正常图片。
CLIP(Text Encoder)
CLIP是一个基于对比学习的文本图像预训练方法,是一种基于对比学习的多模态模型。文本输入进去后首先经过tokenize编码变成数字,然后在送入Text Transformer得到生成图片的条件。
作为文生图模型,Stable Diffusion中的文本编码模块直接决定了语义信息的优良程度,从而影响到最后图片生成的多样性和可控性。
在这里,多模态领域的神器——CLIP(Contrastive Language-Image Pre-training),跨过了周期,从传统深度学习时代进入AIGC时代,成为了SD系列模型中文本和图像之间的连接通道。并且从某种程度上讲,正是因为CLIP模型的前置出现,更加快速地推动了AI绘画领域的繁荣。
那么,什么是CLIP呢?CLIP有哪些优良的性质呢?为什么是CLIP呢?
首先,CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;而Image Encoder主要用来提取图像的特征,可以使用CNN/vision transformer模型(ResNet和ViT)作为Image Encoder。与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
与U-Net的Encoder和Decoder一样,CLIP的Text Encoder和Image Encoder也能非常灵活的切换;其庞大图片与标签文本数据的预训练赋予了CLIP强大的zero-shot分类能力。
灵活的结构,简洁的思想,让CLIP不仅仅是个模型,也给我们一个很好的借鉴,往往伟大的产品都是大道至简的。更重要的是,CLIP把自然语言领域的抽象概念带到了计算机视觉领域。
潜空间(Latent)
把“人话”转成数字后,我们就需要利用这些数字生成图片了。
一张图片包含的信息十分多,一张512×512的图片就有巨量的数据,假设是一张RGB的图,有512×512个像素点,每个像素点由R、G、B组成不同颜色,就还要乘3。
这就导致运算量过大,因此需要将数据送入“潜空间”。这个潜空间可以简单理解成压缩过的图片数据。图形数据的处理全部在这个潜空间之内,这样我们需要计算的数据就会少得多。
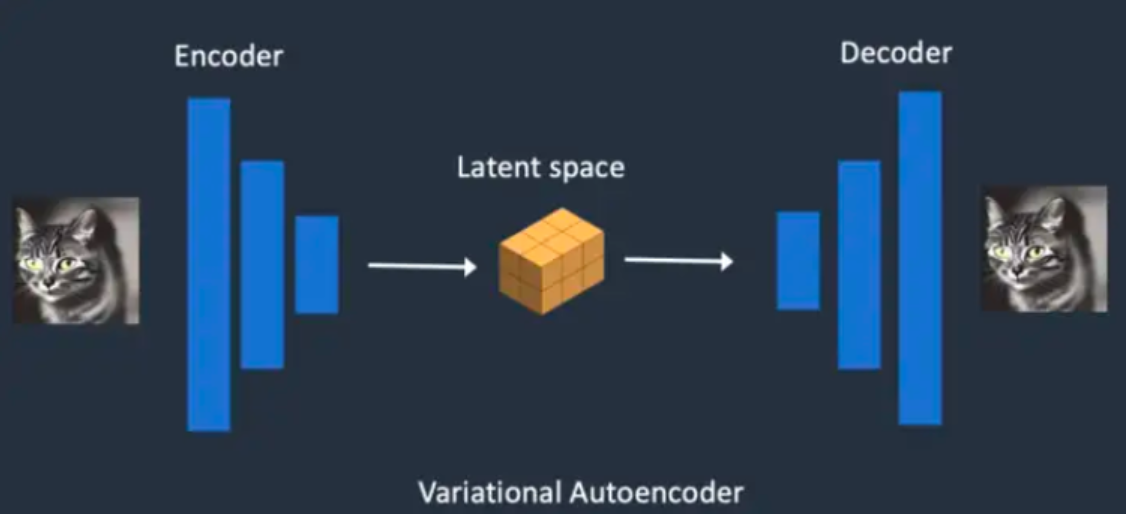
变分自编码器(VAE)
潜空间得到生成图片的数据后,需要通过VAE进行进一步转换+扩大,因为潜空间种的数据时经过压缩的,不是平常能看到的正常图片,这就是我们常见的VAE的作用。
学习链接:

