
半监督主动学习论文阅读
开学了,摆烂了一个寒假,之后慢慢佛系更新吧~
Online Active Learning for Soft Sensor Development using Semi-Supervised Autoencoders
数据驱动的软传感器广泛用于工业和化学过程,以预测难以测量的过程变量,这些变量的真实值在日常操作中难以跟踪。这些传感器使用的回归模型通常需要大量标记示例,但考虑到质量检查所需的大量时间和成本,获取标记信息可能非常昂贵。在这种情况下,主动学习方法可能非常有益,因为它们可以建议最有用的标签进行查询。然而,为回归提出的大多数主动学习策略都集中在离线设置上。在这项工作中,我们将其中一些方法应用于基于流的场景,并展示如何使用它们来选择信息量最大的数据点。我们还演示了如何使用基于正交自动编码器的半监督架构来学习低维空间中的显着特征。 Tennessee Eastman Process (TEP)用于比较所提出方法的预测性能。
1.Introduction
该部分主要讲了软测量的基本情况,未标记数据较多,然后引出了主动学习。主动学习对于减少实现令人信服的预测性能所需的标签数量变得越来越有用。基于主动学习的抽样方案使用一些评估标准来评估未标记数据点的信息量,并优先标记最有用的实例来构建模型。
然后按照未标记数据输入学习器的方式介绍了主动学习的三种类别:
1.membership query synthesis
它允许学习者查询合成生成实例的标签,而不是从过程分布中采样的标签。membership query synthesis与其他AL(active learning)不同点在于并不是从整个样本数据集选择合适的样本进行query,而是从样本空间进行特征级别的采样从而合成未label数据样本进行query(例如如火如荼的GAN策略)。
2.streambased active learning(基于流的主动学习)
替代样本synthesis的另外一个策略就是进行样本空间的样本级别的采样,学习器针对序列样本逐一的进行query or 丢弃的决策。query策略可以分为以下几种:
- 量化“informativeness measure”,针对info大的样本提升query采样率
- region of uncertainty ,针对不确定性高的样本提升query采样率
两种query策略的区别在于如何的度量难以学习的样本
3.pool-based active learning(基于池的主动学习)
它描述了一次收集大量未标记数据并提供给学习器的情况,学习者可以对所有数据点进行排序并选择信息量最大的数据点。
更加常见的一个业务场景是:存在一个小size的标注样本集合 L 和一个大size的未标注样本集合 U,然后根据informativeness measure从 U(也可以对选取 U 的一些子集)中选取样本进行query。
Stream-based和pool-based有什么不同呢?
The main difference between stream-based and pool-based active learning is that the former scans through the data sequentially and makes query decisions individually, whereas the latter evaluates and ranks the entire collection before selecting the best query. While the pool-based scenario appears to be much more common among application papers, one can imagine settings where the streambased approach is more appropriate
关于主动学习详细解释见
本文主要关注基于流的主动学习,因为基于流的主动学习主要难点在于学习器在决定查询哪些标签之前无法观察所有可用的观察结果,这种情况跟工业过程类似。
2.Background
该部分主要讲的是一些公式,假设了一个带有n个观测值的标记数据集
,然后建立的回归模型如下:
其中x0为截距项,x1~xp是p个过程变量,通过下式MSE来给估计参数
之后介绍了马氏距离、Query By Committee(QBC)以及Expected Model Change(EMC)
Mahalanobis Distance:
如果我们只检查特征空间,我们在为训练集 L 收集实例时可能追求的一个理想属性是确保观察之间的多样性。广泛用于统计过程控制 (SPC) 以检测异常数据点的 Hotelling T 2 控制图 (Hotelling, 1947) 可以实现这一点。正如我们在 SPC 中所做的那样,在这种情况下,我们使用马氏距离来衡量新的未标记实例与当前训练集 L 中的观察值之间的差异。新的未标记实例 x 的 Hotelling T2 统计量计算为
x-和S分别对应L的样本均值向量和样本协方差矩阵。葛志强等已将该方法应用到主成分回归(PCR)模型,他提出了一个依赖于T2统计量和平方预测误差的抽样指数。在这种情况下采样函数表示为 argmaxxT2(x)
Query By Committee(QBC):
以前的方法只考虑特征空间,但QBC试图评估响应的不确定性。该策略最初是未分类问题引入的,后来被Burbidge等人扩展到回归任务。通过构建在原始训练集 B(K) = {f1, f2, …, fK} 的引导副本上训练的回归模型集合,我们可以近似预测方差的分布。一旦构建了集成,我们就可以测量委员会成员对每个未标记的观察值 x 做出的预测的方差。此方差或歧义计算为
其中 yK(x) 是整体成员所做预测的平均值。然后采样函数变为 argmaxxa(x)。关键是,如果许多模型不同意与实例关联的标签,那么该实例就是一个模棱两可的实例。
Expected Model Change(EMC):
思想:假设知道 unlabelled instance的label,将这个instance丢入到model中会对model 产生最大的影响。
该算法量化了当前模型参数与新模型参数之间的差异,并选择一个导致最大变化的未标记实例。
L+ = L∪(x+,y+),公式后半项表示用在L上训练的模型和用在L+上训练的模型测量的损失之间的差异。
3.Proposed Approach
该部分主要讲一些设定以及模型结构。
鉴于不可能实时对未标记的实例进行排序并确定性地优化采样标准,我们建议利用未标记的数据对传入数据点的信息量施加阈值或控制上限 (UCL)。未标记的数据池可以通过观察一段时间的过程而不对产品信息 y 进行采样或使用历史数据库 H = {(xi), xi ∈ Rp} 形式的现有数据来获取。基于池的主动学习和在线主动学习之间的主要区别在于,无法再查询与 H 有关的观察标签,因为它们仅以数字形式存在,并且相关的物理部分或组件不再可用。 H 中的数据用于估计等式 2、3 和 4 中的标准所采用的统计分布。在本研究中,我们采用高斯核进行核密度估计。然后通过指定适当的采样率 α 来确定 UCL。对于给定的标准 J ,阈值定义为
J为采样标准,本文使用之前提到的马氏距离、QBC以及EMC作为标准,仅收集α百分比的最有信息的数据点。作者还提到建议通过在历史数据H上训练自编码器来使用半监督架构。通过半监督学习可以利用所有可用的未标记数据并学习如何提取相关信息比原始输入特征更好的预测特征。
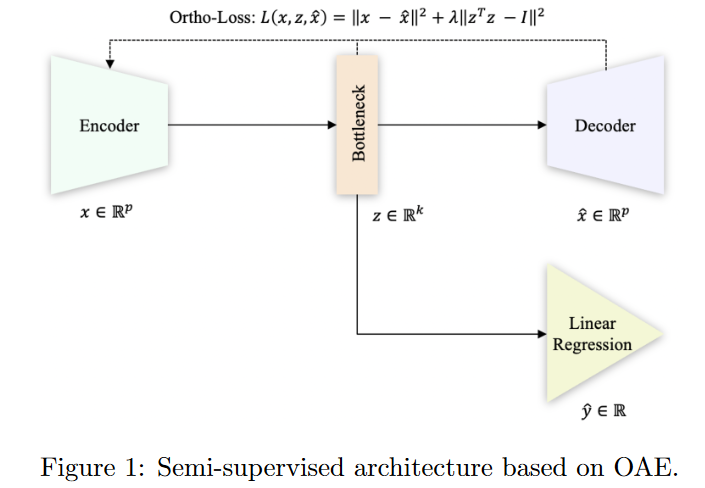
4.Experiments
实验采用了Tennessee Eastman Process (TEP)用于比较所提出方法的预测性能。
实验结果如下:
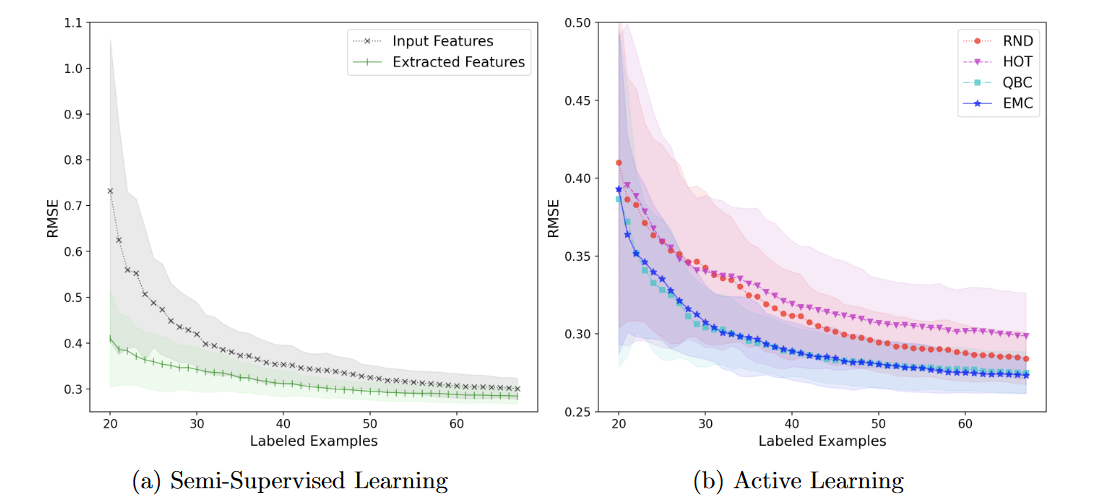
(a) 显示了使用原始过程变量和 OAE 提取的特征进行随机抽样的学习曲线,(b) 显示了不同主动学习方法的学习曲线: RND、Hotelling T2 (HOT) 、QBC 和EMC。
可以看出OAE效果较好,文中解释可能是因为OAE能够在其编码特征中表达数据中的非线性关系,以及随着提取的特征,我们有相同数量的观测来估计较少数量的参数。
在b中四种方法均使用了OAE提取特征,能够看出EMC和QBC在推荐信息量最大的数据点方面始终优于被动随机方法(RND)。马氏距离(HOT)会使预测变差,作者认为可能是由于具有高T2统计数据的数据点可能是异常值,异常值包含在训练集中最终会降低性能。
5.Conclusion
在这项工作中,我们提出了一种基于 OAE 的半监督模型,用于提取相关特征并减少多重共线性。最重要的是,我们回顾并调整了一些最广泛使用的线性回归主动学习策略的在线设置。该分析证明了如何正确使用历史数据并考虑预期响应可以更快地减少预测误差。对于未来的研究,我们将考虑更高级的架构,例如 LSTM 自动编码器或转换器,以获得考虑数据时间依赖性的编码特征。
论文链接
Online Active Learning for Soft Sensor Development using Semi-Supervised Autoencoders

