
小样本学习综述
随着大数据时代的到来,深度学习模型已经在图像分类、文本分类等任务中取得了先进成果.但深度学习 模型的成功,很大程度上依赖于大量训练数据.而在现实世界的真实场景中,某些类别只有少量数据或少量标注数据,而对无标签数据进行标注将会消耗大量的时间和人力.与此相反,人类只需要通过少量数据就能做到快速 学习.例如,一个五六岁的小孩子从未见过企鹅,但如果给他看过一张企鹅的图像,当他进入动物园看到真正的 企鹅时,就会马上认出这是自己曾经在图像上见过的“企鹅”,这就是机器学习和人类学习之间存在的差距.受到 人类学习观点的启发,小样本学习(few-shot learning)的概念被提出,使得机器学习更加靠近人类思维.
何为小样本学习?
小样本学习也叫做少样本学习(low-shot learning),其目标是从少量样本中学习 到解决问题的方法.与小样本学习相关的概念还有零样本学习(zero-shot learning)等.零样本学习是指在没有 训练数据的情况下,利用类别的属性等信息训练模型,从而识别新类别.
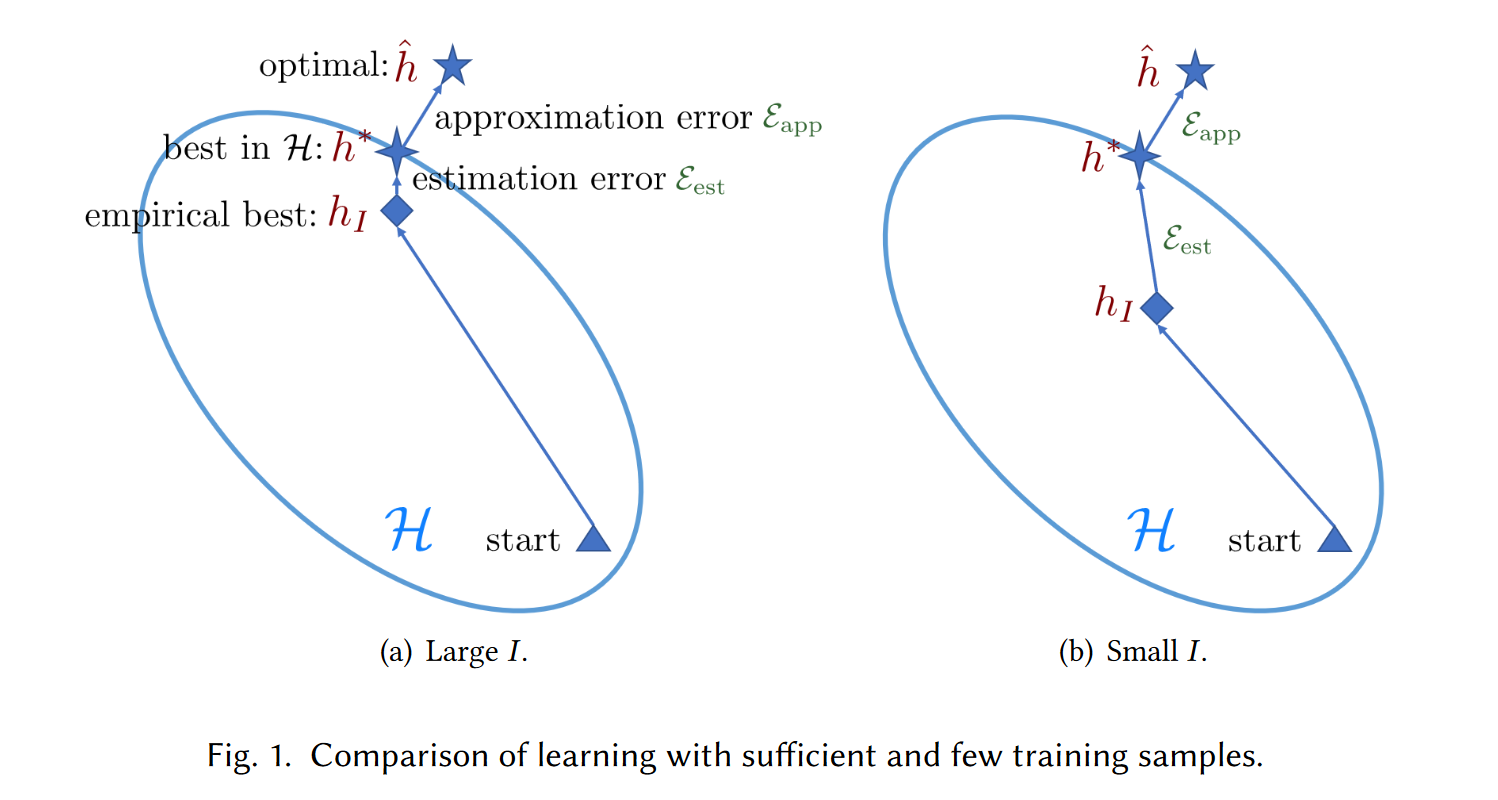 即:仅使用少量标签数据训练模型,使之具有良好的泛化能力。
即:仅使用少量标签数据训练模型,使之具有良好的泛化能力。
小样本学习的方法
小样本之所以能够利用少量数据来表现出良好的泛化能力,是因为它可以借助一个外力,这个外力就是“先验知识”(prior knowledge)。
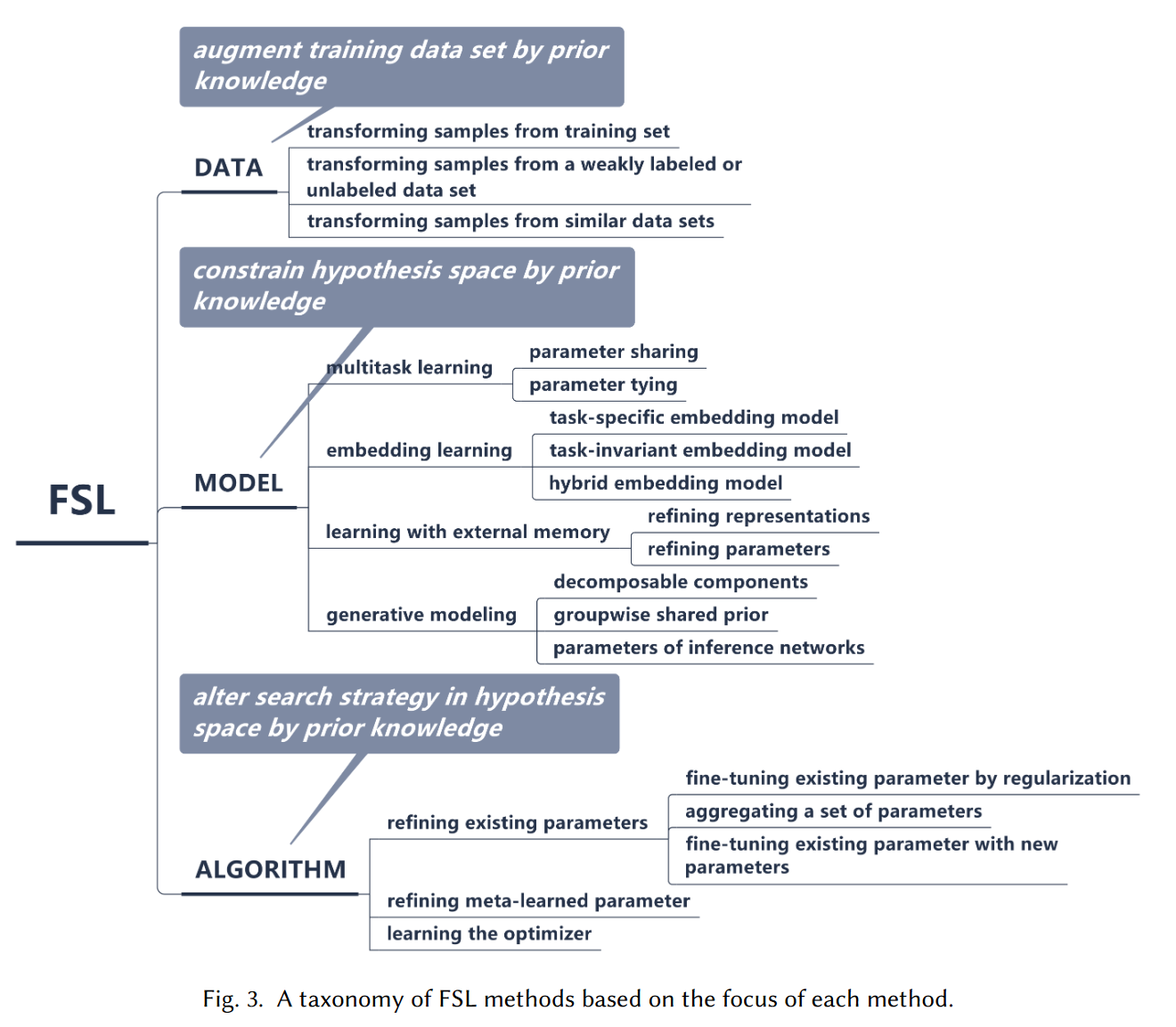
当前小样本学习的先验知识主要来源于三个方面:数据、模型、算法,根据这三方面,小样本也学习的整体方向也可大致分为基于数据增强的方法、基于模型改进的方法、基于算法优化的方法。
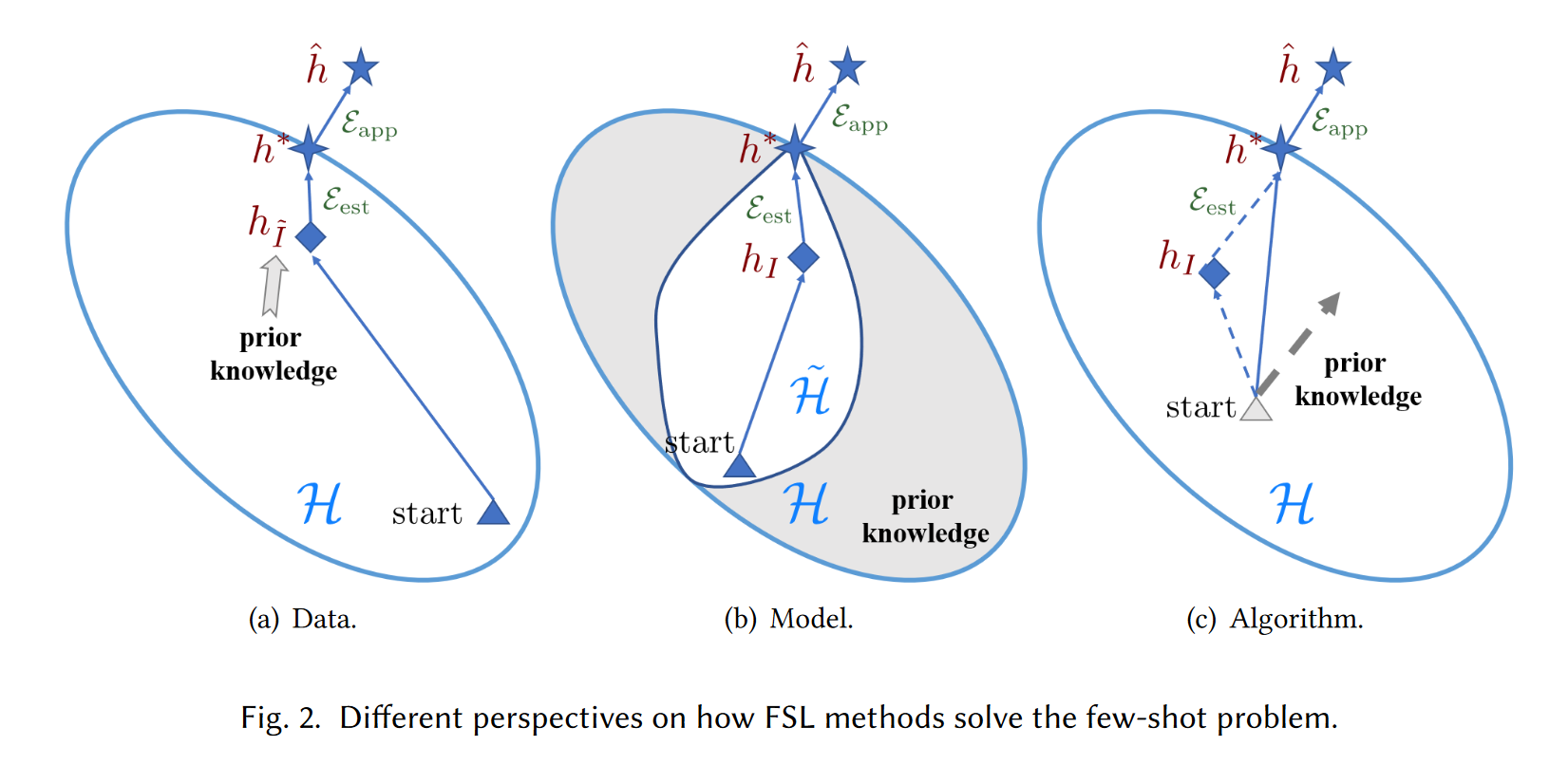
(a):主要方法为数据增强,也就是扩充样本,可以通过标准的机器学习模型和算法来增强数据,并且可以获得更准确的经验风险最小化器hI^
(b):该方法主要通过使用先验知识来约束假设空间H的复杂性,从而让假设空间H比比之前小得多(H~部分),因为根据先验知识他们不太可能包含参数化最优的h,如果假设空间变为H~,那么训练集的数据就足以学习到可靠的hI,从而找到h
(c):该方法通过使用先验知识来搜索H中的最佳h*的参数θ,先验知识提供良好的初始化数据(图c中的三角形)或指导搜索步骤(图c中的虚线箭头)来改变搜索策略。后者中的搜索步骤会受先验知识和经验风险最小化的影响。
下图为三种方法的小样本学习方法分类:
基于数据增强的方法
FSL通过使用先验知识扩充训练集,从而让数据足以获得可靠的hI
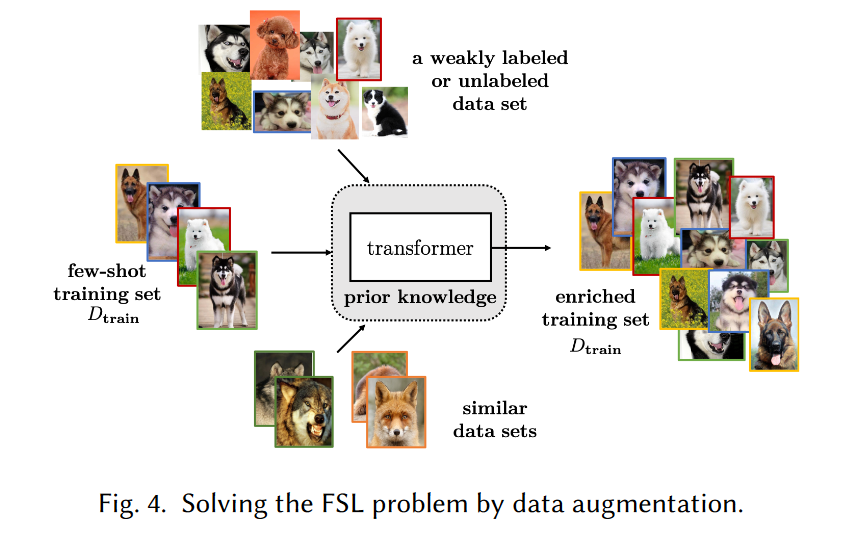
Transforming Samples from Dtrain
该策略通过将每个 (xi , yi ) ∈ Dtrain 转换为多个具有变化的样本来增强 Dtrain。转换过程作为先验知识包含在经验 E 中,以便生成额外的样本。
Transforming Samples from a Weakly Labeled or Unlabeled Data Set
该策略通过从弱标记或未标记的大型数据集中选择具有目标标签的样本来增强 Dtrain。
例如,监控摄像头拍摄的照片中,有人、有车、有路,但都没有该策略通过从弱标记或未标记的大型数据集中选择具有目标标签的样本来增强 Dtrain。标注。另一个例子是用于长演示的视频。这包含说话者的一系列手势,但都没有明确注释。由于这样的数据集包含大量样本变化,因此将它们扩充到 Dtrain 有助于描绘更清晰的 p(x, y)。
此外,收集这样的数据集更容易,因为不需要人工进行标记。然而,尽管收集成本很低,但一个主要问题是如何选择具有目标标签的样本以增强到 Dtrain。有人为Dtrain中的每个目标标签学习了一个样本SVM,然后用于预测来自弱标记数据集的样本标签,并将具有目标标签的样本添加到Dtrain。还有一种方法没有学习分类器,直接使用标签传播来标记未标记的数据集。
Transforming Samples from Similar Data Sets
该策略通过聚合和调整来自相似但更大数据集的输入-输出对来增强 Dtrain。
生成对抗网络 (GAN) 旨在生成无法区分的合成 x~ 从许多样本的数据集中聚合而成 。它有两个生成器,一个将few-shot类的样本映射到large-scale类,另一个将large-scale类的样本映射到few-shot类(弥补GAN训练中样本不足的问题)
以上三类数据增强方面的方法在实际中要根据已有的样本以及其他因素来具体确定使用哪种方法。
总结表格如下:

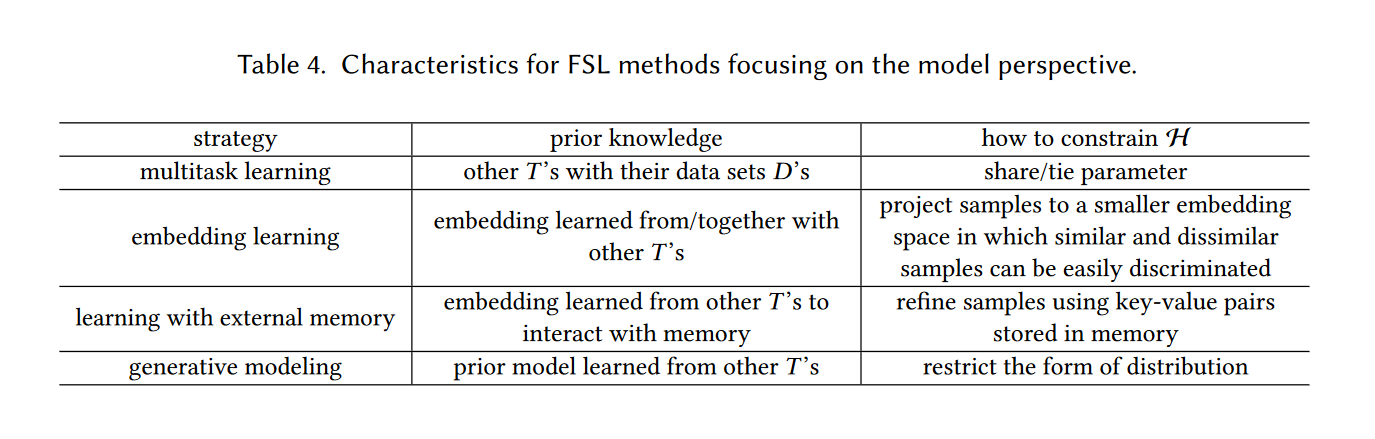
基于模型改进的方法
每个模型经过迭代都会得到近似解,而当样本有限时,在假设空间搜索解就变得困难。这类方法为了缩小假设空间,主要有四种方法,之后分别介绍四种方法
multitask learning
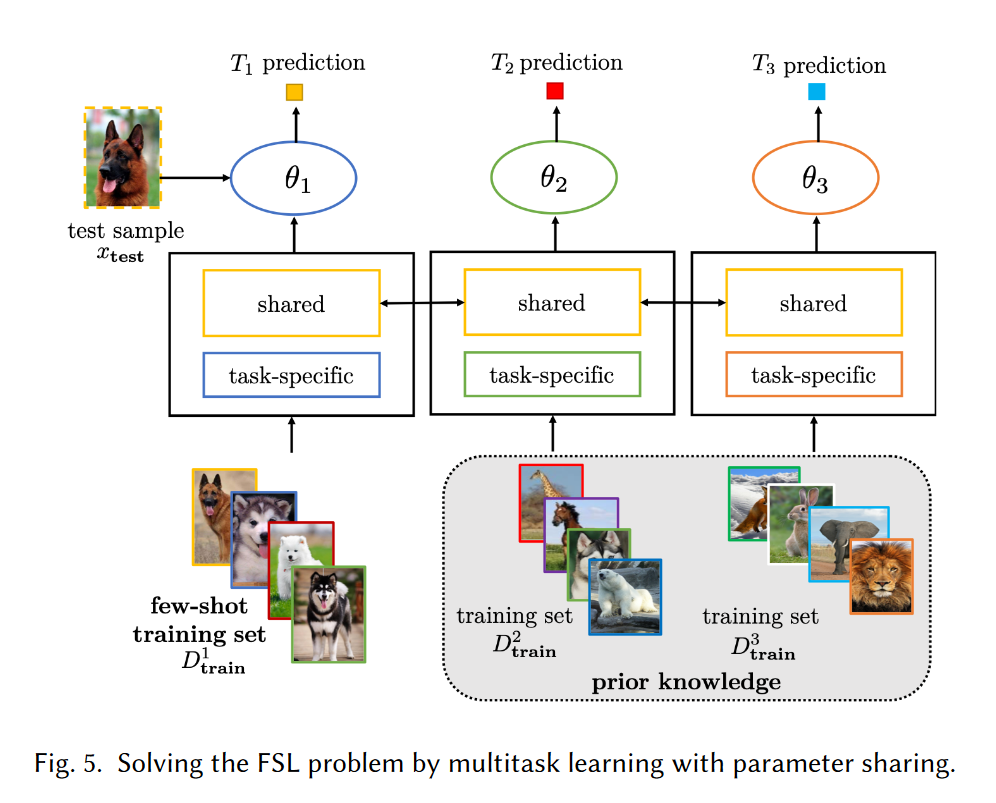
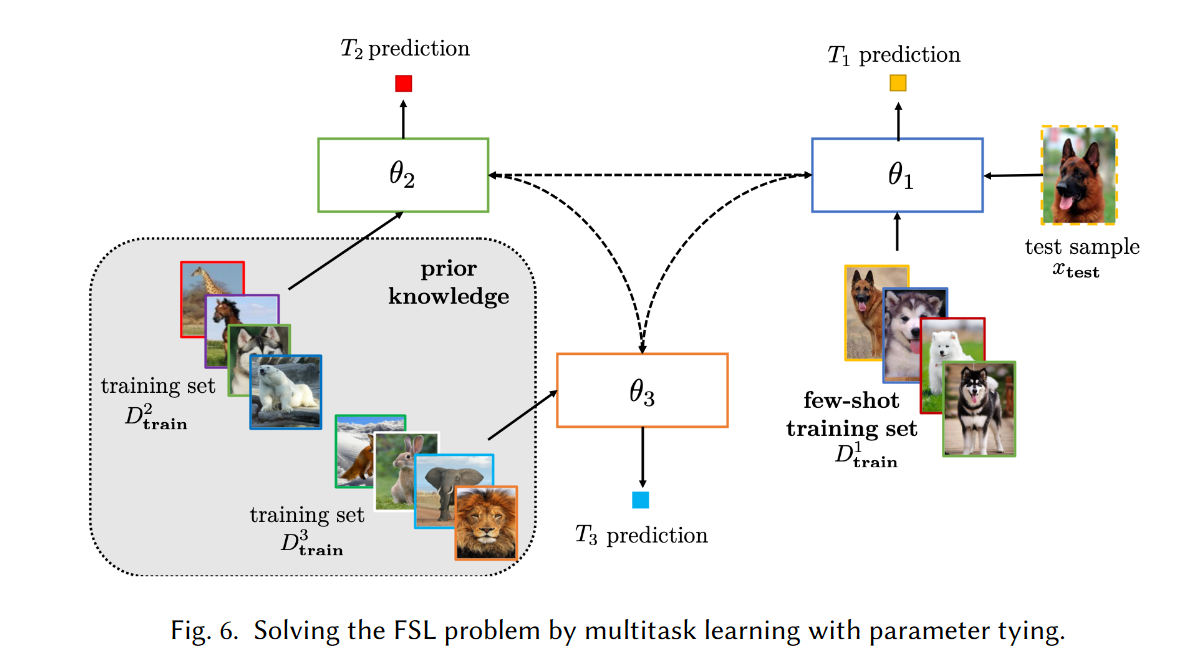
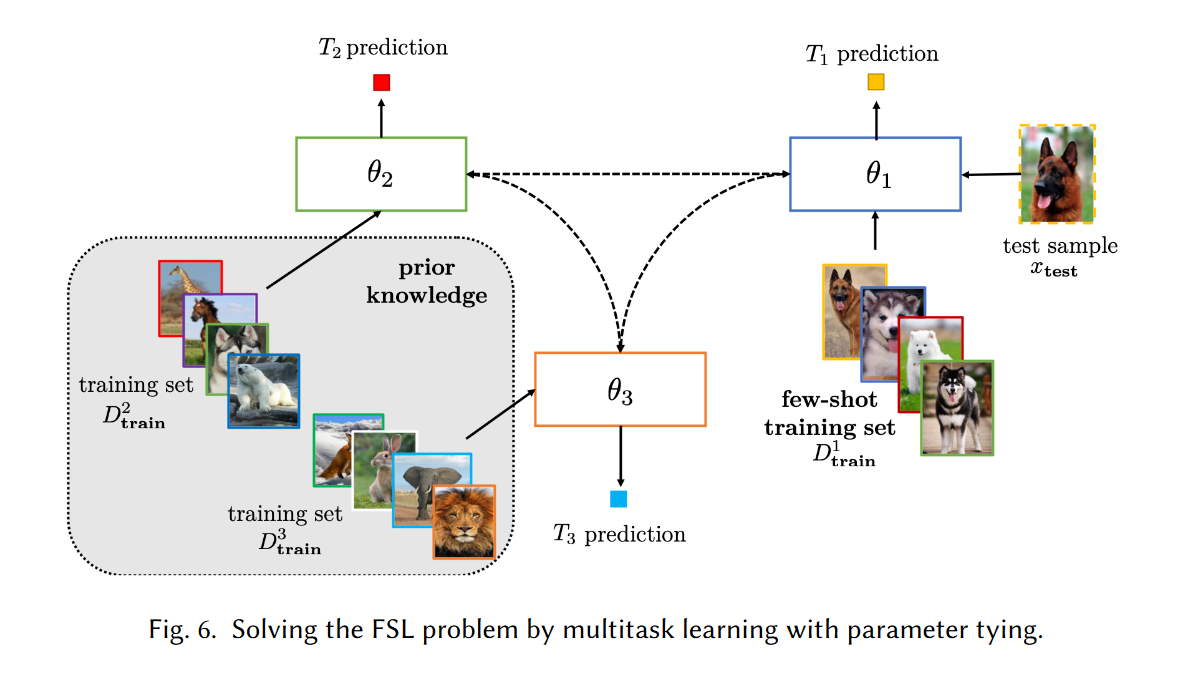
在存在多个相关任务的情况下,多任务学习通过利用任务通用信息和任务特定信息同时学习这些任务。因此,它们可以自然地用于 FSL。这种模型可以处理多个任务,因此也就兼备了模型的普适性和一般性。在处理多个任务时,模型的参数可以是共享的,也可以是相关联的。
共享参数模型
关联参数模型
embedding learning
将样本映射到一个低维度空间,从而达到了缩小假设空间的效果,然后就可以通过少量的样本求出模型在该假设空间下的近似解。根据映射到低维空间的方法又分为三类:任务特定型(结合任务的具体特点进行映射)、通用型、结合型(结合任务和通用)
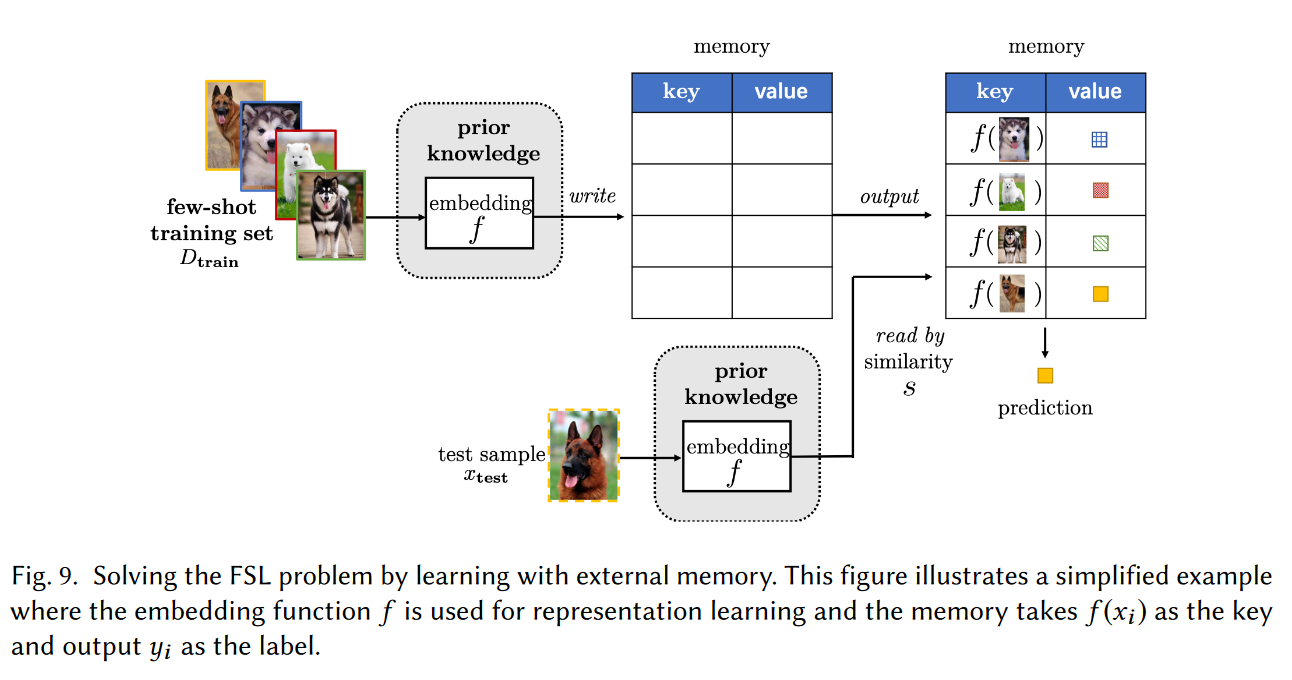
learning with external memory
通过对小样本数据集学习得到知识,然后存储到外部,对于新样本,都使用存储在外部的知识进行表示,并根据表示来完成匹配。这种方法大大降低假设空间
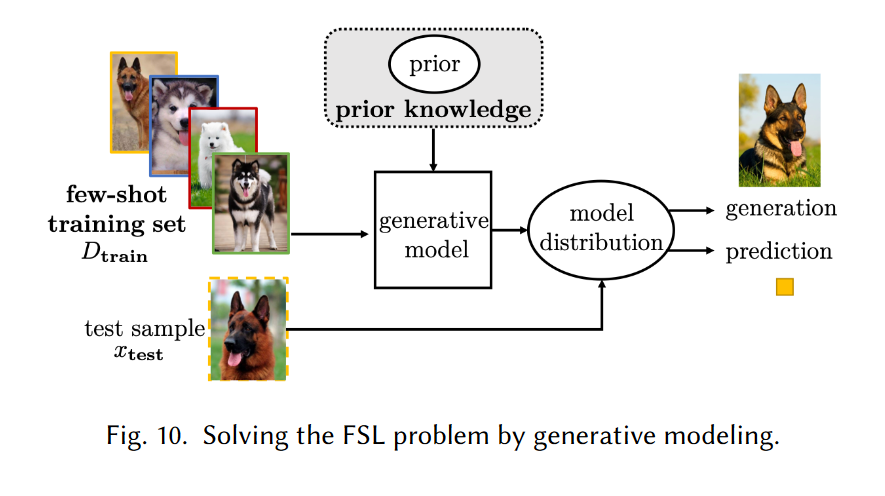
generative modeling
生成模型学习小样本数据集的数据分布,并可将其用于各种任务。
总结表格如下:
基于算法优化的方法
这类方法的核心是通过改进优化算法来更快地搜索到合适解。主要方法有三种:
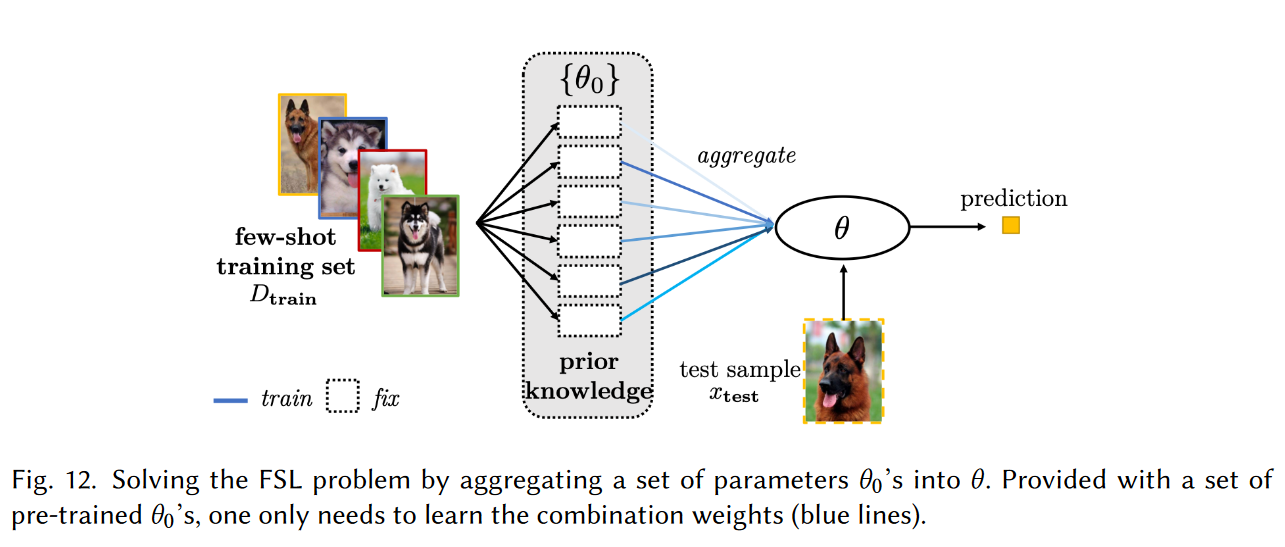
Refining Existing Parameters
这种方法从参数初始化的角度着手,主要思路是借助已训练好的模型参数来调整小样本模型的参数,例如:在大数据集训练好模型来初始化小样本模型;聚合其他已训练好的模型到一个模型;给已训练好的模型加一些特用于小样本任务的参数;等等。
Refining Meta-Learned Parameter
元学习(meta-learning)是当下很火的一个研究方向,它的思想是学习如何学习。它的结构一般是由一个底层模型和一个顶层模型组成,底层模型是model的主体,顶层模型是meta-learner。更新参数时,它除了要更新底层model,还要更新meta参数。改善策略大致有三类:1)结合不同特定任务模型参数来对新任务的参数进行初始化;2)对模型不确定性建模,以备后续提升;3)改进参数调整流程。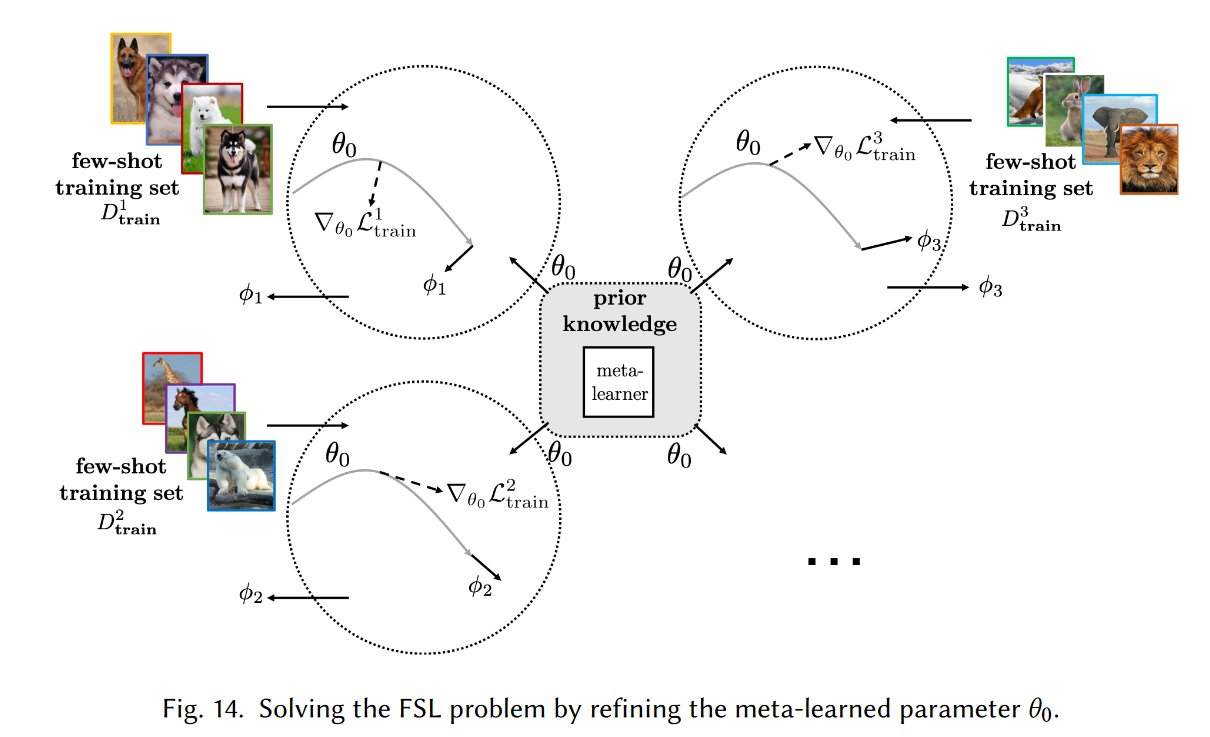
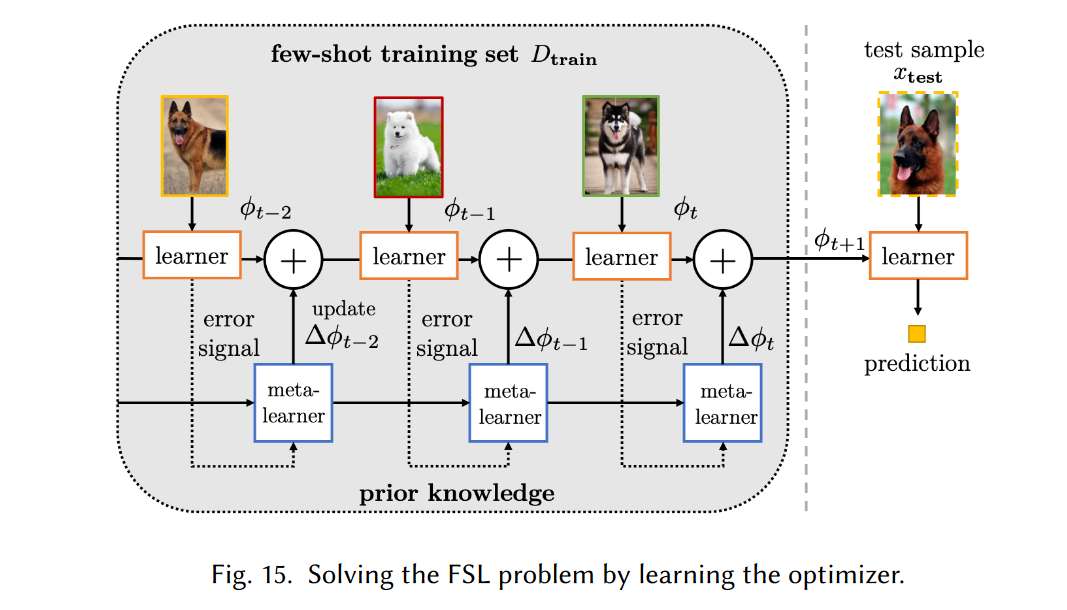
Learning the Optimizer
在上一节中元学习器Θ0充当了带有数据D的T~P(T)良好初始化,并且通过几个有效的梯度下降步骤将其调整为特定于任务的参数Φ。本节中不使用梯度下降,而是学习可以直接输出更新的优化器。这样优化器每次都会迭代更新上一次的模型参数,从而应用在新的测试数据上。
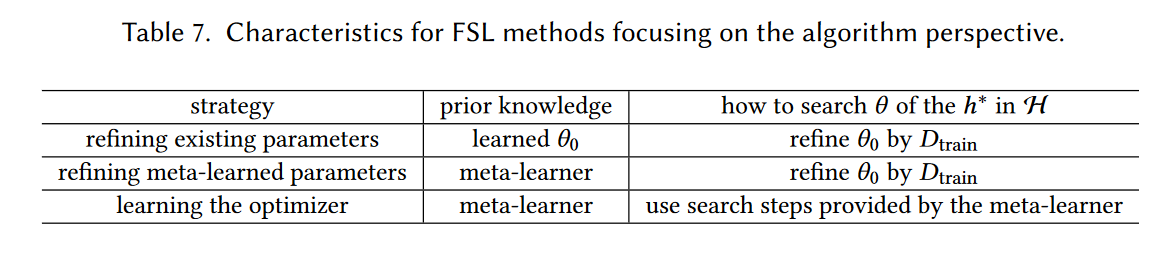
总结表格如下:
参考论文链接
Generalizing from a Few Examples: A Survey on Few-Shot Learning

