
自编码器(AutoEncoder)
自编码器原理与结构
原理
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning 。
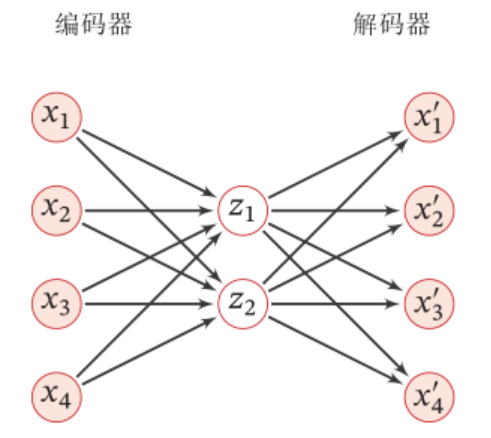
自编码器包含编码器(encoder)和解码器(decoder)两部分。按学习范式,自编码器可以被分为收缩自编码器(contractive autoencoder)、正则自编码器(regularized autoencoder)和变分自编码器(Variational AutoEncoder, VAE),其中前两者是判别模型、后者是生成模型 。按构筑类型,自编码器可以是前馈结构或递归结构的神经网络。
自编码器具有一般意义上表征学习算法的功能,被应用于降维(dimensionality reduction)和异常值检测(anomaly detection)。包含卷积层构筑的自编码器可被应用于计算机视觉问题,包括图像降噪(image denoising)、神经风格迁移(neural style transfer)等。
一个简单的自编码器结构如下:
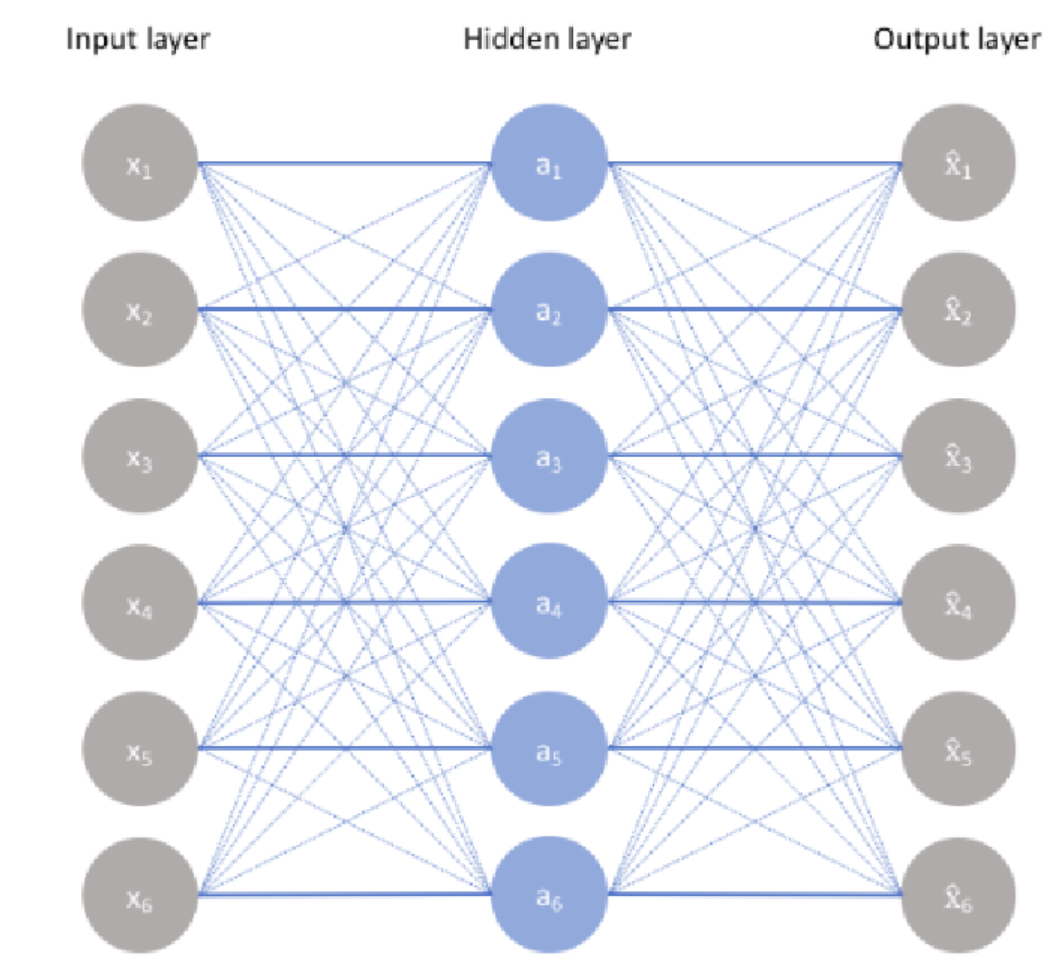
上述结构输入层到隐藏层为Encoder(编码器),隐藏层到输出层为Decoder(解码器)。
常用的降维方法有主成分分析法(PCA),PCA降维的原理可参考降维基础知识(样本均值、样本方差、中心矩阵)与PCA(最大投影方差,最小重构代价,SVD分解)
自编码器降维则是通过让隐藏层神经元的数目远低于输入层,那么我们就可以用更少的特征(神经元)去表征输入数据,从而达到降维目的。
结构
对于样本x,自编码器的中间隐藏层的活性值为x的编码,即:
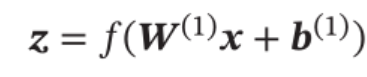
自编码器的输出为重构的数据:
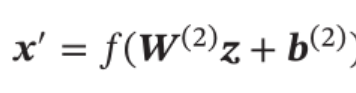
其中,W (1),W(2),b(1),b(2)是自编码器网络的参数,参数经梯度下降训练得到。
搭建一个自编码器需要以下几个步骤:
1.搭建编码器
2.搭建解码器
3.设定一个损失函数
4.训练
自编码器分类
普通自编码器
输入与输出完全相同,即前面的基本结构。
堆叠自编码器
对于很多数据来说, 仅使用两层神经网络的自编码器还不足以获取一种好的数据表示。为了获取更好的数据表示, 我们可以使用更深层的神经网络。深层神经网络作为自编码器提取的数据表示一般会更加抽象, 能够更好地捕捉到数据的语义信息。
在实践中经常使用逐层堆叠的方式来训练一个深层的自编码器,称为堆叠自编码器(Stacked Auto-Encoder, SAE)。堆叠自编码器一般可以采用逐层训练(Layer-Wise Training)来学习网络参数。
举一个具体的例子:
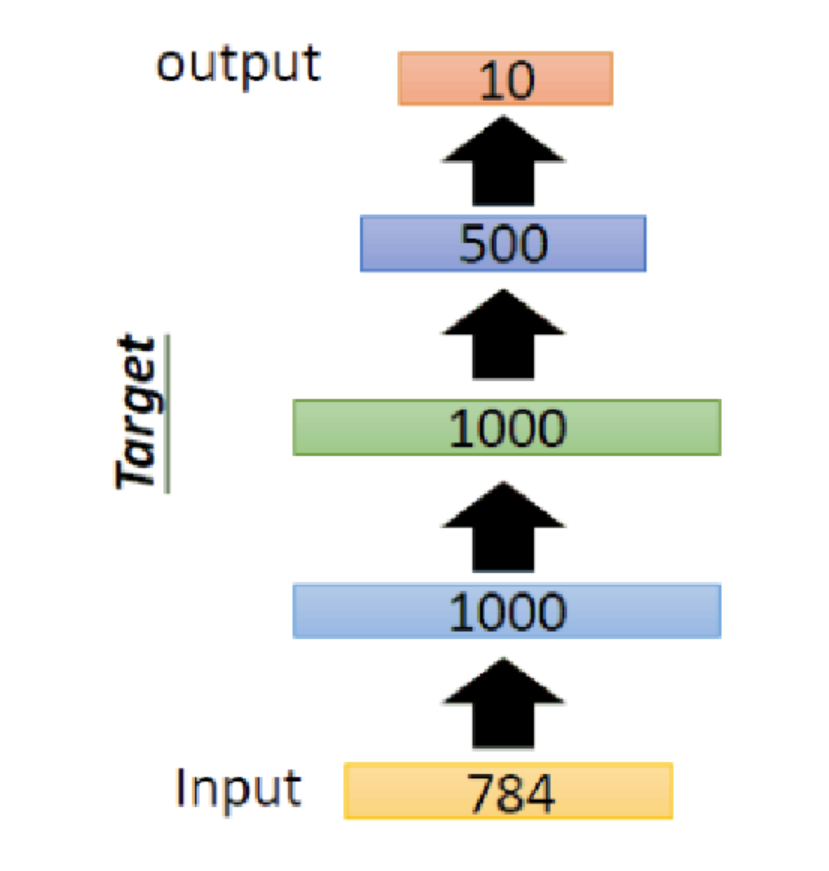
可以看到,相比于普通的自编码器,我们将隐藏层的个数从1增加到3,其实就是三个普通自编码器堆叠而成。
训练过程如下:
第一个自编码器:784->1000->784。训练完毕后,固定参数和中间隐层的结果,去掉输出层和相应的权值偏置,然后将隐藏层1000作为第二个自编码器的输入。
第二个自编码器:1000->1000->1000。训练完毕后,固定参数和中间隐层的结果,去掉输出层和相应的权值偏置,然后再将隐藏层1000作为第三个自编码器的输入。
第三个自编码器:1000->500->1000。训练完毕后,固定参数和中间隐层的结果,去掉输出层和相应的权值偏置。
在第三个自编码器隐藏层后面加一个分类器(softmax),进行解码恢复。
三个自编码器训练完毕后,最后要进行的是整体的反向调优训练,即整体网络使用反向传播进行训练,对参数进行微调。
降噪自编码器(Denoising Auto-Encoder)
我们使用自编码器是为了得到有效的数据表示, 而有效的数据表示除了具有最小重构错误或稀疏性等性质之外,还可以要求其具备其他性质,比如对数据部分损坏(Partial Destruction)的鲁棒性。高维数据(比如图像)一般都具有一定的信息冗余,比如我们可以根据一张部分破损的图像联想出其完整内容。因此, 我们希望自编码器也能够从部分损坏的数据中得到有效的数据表示, 并能够恢复出完整的原始信息,降噪自编码器便应运而生。
降噪自编码器(Denoising Auto-Encoder)就是一种通过引入噪声来增加编码鲁棒性的自编码器。DAE给输入数据添加随机的噪声扰动,如给输入x添加采样自高斯分布的噪声得到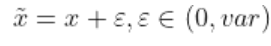
添加噪声后,网络需要从x~学习到数据的真实隐藏变量z,并还原出原始的输入x
稀疏自编码器(Dropout Auto-Encoder)
一般来说,自编码器的隐层节点数小于输入层的节点数,比如前面所述,为了达到降维的目的,一般使隐藏层神经元个数小于输入层神经元个数。但假设我们并不限制隐藏层神经元个数,而是限制了其中一部分神经元的活性。
Dropout Auto-Encoder 通过随机断开网络的连接来减少网络的表达能力,防止过拟合,通过在网络层,中插入 Dropout 层即可实现网络连接的随机断开。
对抗自编码器(Adversarial Auto-Encoder)
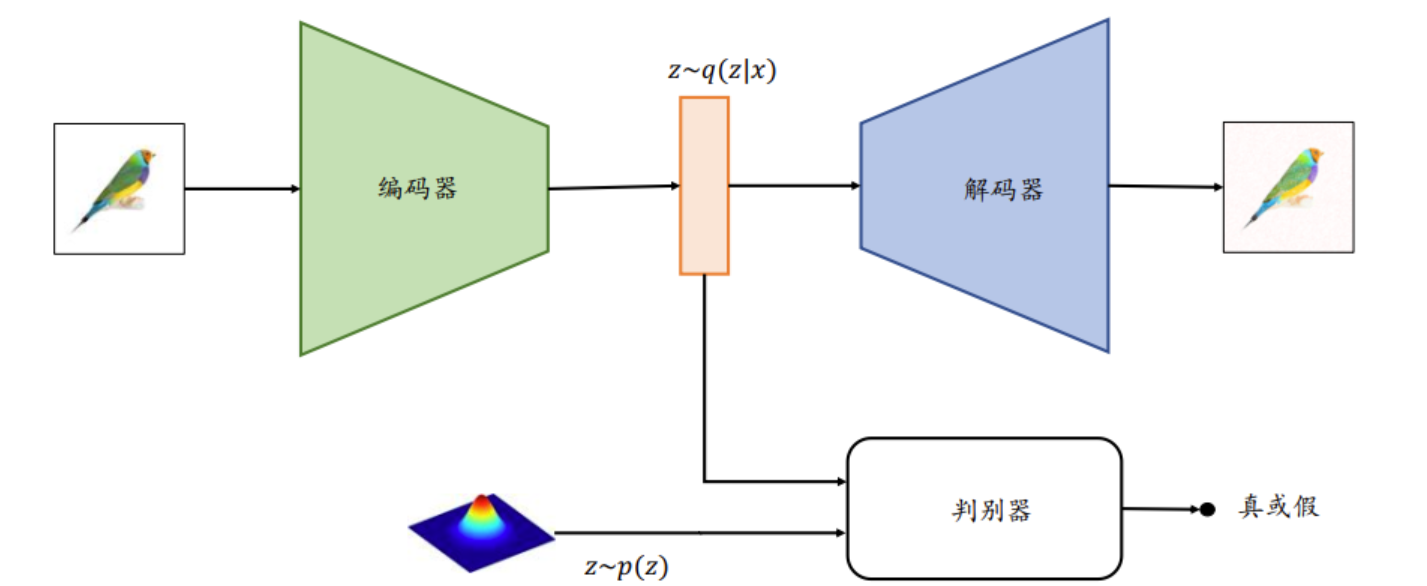
为了能够方便地从某个已知的先验分布中𝑝(𝒛)采样隐藏变量𝒛,利用𝑝(𝒛)来重建输入, 对抗自编码器(Adversarial Auto-Encoder)利用额外的判别器网络(Discriminator, 简称 D网络)来判定降维的隐藏变量𝒛是否采样自先验分布𝑝(𝒛), 判别器网络的输出为一个属于[0,1]区间的变量,表征隐藏向量是否采样自先验分布𝑝(𝒛):所有采样自先验分布𝑝(𝒛)的𝒛标注为真, 采样自编码器的条件概率𝑞(𝒛|𝒙)的𝒛标注为假。通过这种方式训练,除了可以重建样本,还可以约束条件概率分布𝑞(𝒛|𝒙)逼近先验分布𝑝(𝒛)。
变分自编码器(Variational AutoEncoders)
基本的自编码器本质上是学习输入𝒙和隐藏变量𝒛之间映射关系, 它是一个判别模型(Discriminative model),并不是生成模型(Generative model)。
变分自编码器(Variational AutoEncoders,VAE):给定隐藏变量的分布P(𝒛), 如果可以学习到条件概率分布P(𝒙|𝒛), 则通过对联合概率分布P(𝒙, 𝒛) = P(𝒙|𝒛)P(𝒛)进行采样, 生成不同的样本
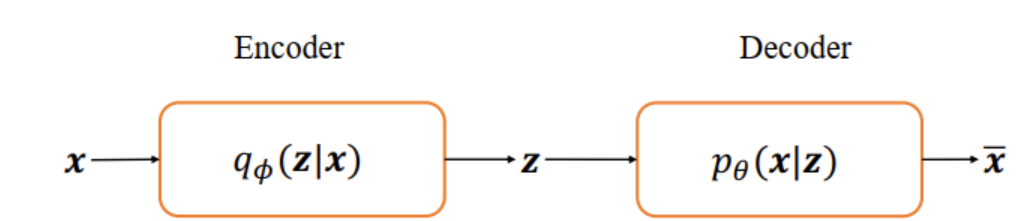
从神经网络的角度来看, VAE 相对于自编码器模型,同样具有编码器和解码器两个子网络。解码器接受输入𝒙, 输出为隐变量𝒛;解码器负责将隐变量𝒛解码为重建的𝒙。 不同的是, VAE 模型对隐变量𝒛的分布有显式地约束,希望隐变量𝒛符合预设的先验分布P(𝒛)。在损失函数的设计上,除了原有的重建误差项外,还添加了隐变量𝒛分布的约束项。
从概率的角度,假设数据集都采样自某个分布𝑝(𝒙|𝒛), 𝒛是隐藏变量,代表了某种内部特征, 比如手写数字的图片𝒙, 𝒛可以表示字体的大小、 书写风格、 加粗、斜体等设定,它符合某个先验分布𝑝(𝒛),在给定具体隐藏变量𝒛的情况下,可以从学到了分布𝑝(𝒙|𝒛)中采样一系列的生成样本,这些样本都具有𝒛所表示的共性。


