
Transformer
Transformer中的Positional Encoding
输入
词向量的输入
Transformer输入的是一个序列数据,以我爱你为例:Encoder的inputs embedding后需要给每个word的词向量添加位置编码positional encoding。
这样设置位置的原因是因为相同的词语如果出现的位置不同有时候意思会发生很大的变化,比如:我欠他100w和他欠我100w。Transformer是完全基于self-Attention的,但是self-Attention又不能获取词语位置信息,因此我们在输入时需要给每一个词向量添加位置编码。
positional encoding获取过程:
1.可以通过数据训练学习得到positional encoding,类似于训练学习词向量
2.使用正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后的和对应位置的词向量相加,位置向量维度必须和词向量的维度一致。过程如图:
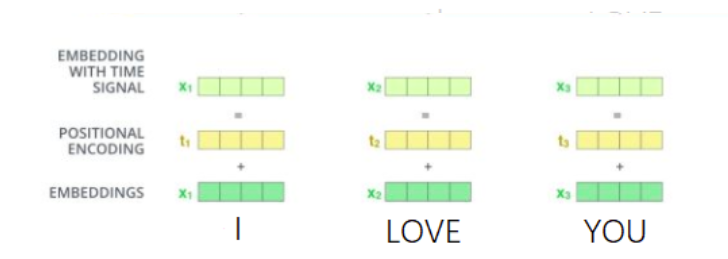
PE(positional encoding)计算公式如下:
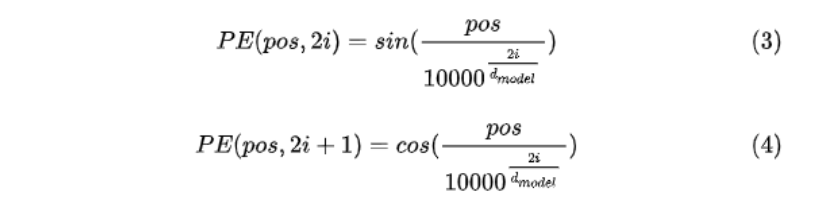
pos表示单词在句子中的绝对位置,pos=0,1,2…,例如:YOU在”I LOVE YOU”中的pos=2;dmodel表示词向量的维度,在这里dmodel=512;2i和2i+1表示奇偶性,i表示词向量中的第几维,例如这里dmodel=512,故i=0,1,2…255。
Attention机制
为什么需要Attention
传统的机器翻译是由encoder和decoder组成,其中encoder和decoder都是一个RNN。翻译过程如下图:
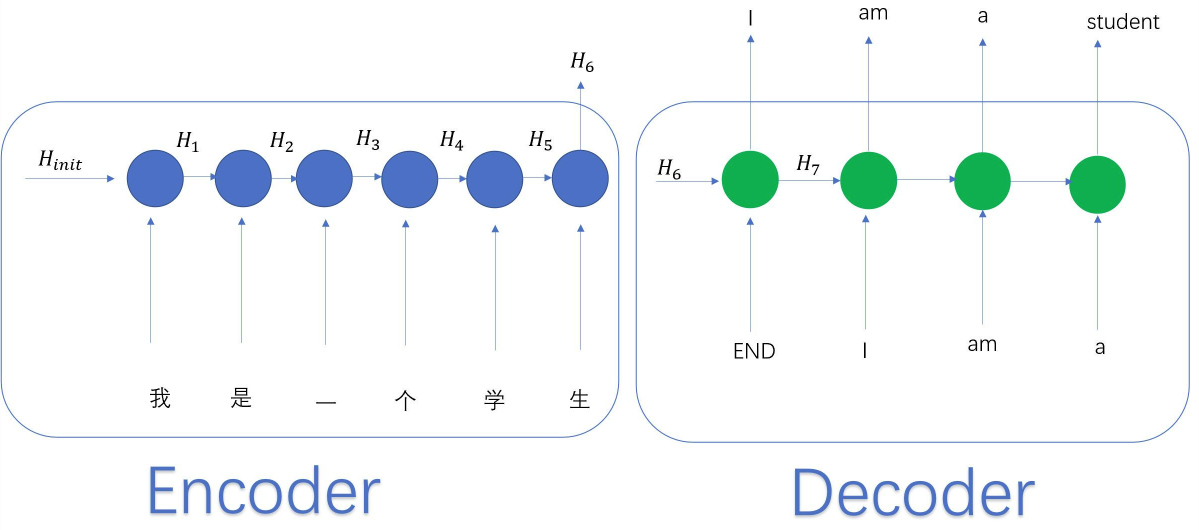
从图中可以看出decoder输出内容取决于encoder的最后一个hidden state,当输入句子很长的时候,前面的信息可能不能很好的被encoder记录。且decoder在输出的时候,不知道当前位置对应着输入的哪一个位置。此外,就算是将encoder 中所有的hidden state 全部给decoder,仍然存在问题,因为两种语言之间单词之间的位置可能没有一一对应的关系,比如“我是一个学生”6个词翻译成英文就只有4个词。为此我们希望模型可以关注输入的相关部分,比如在翻译“我是一个学生”时,我们希望在翻译“student”的时候更多的关注“学生”这个词,而不是其他位置的词,这时候就提出了Attention。
Attention的基本原理
Attention需要encoder中的所有hidden states分别设置权重之后将每一个hidden state根据设置的权重进行加权求和,在将所有加权求和之后的hidden states输入到decoder中。
假设现在decoder正在预测句子中的第i个单词,则将decoder中的第i个hidden state 与 每一个encoder的hidden state 做计算,得到一组‘得分’(注意‘’得分‘’是一个向量且长度应该与输入decoder中的hidden states 数量一致),每一个‘得分’代表了模型在预测当前位置的单词时的注意力,得分越高,模型对其的注意力也就越大。然后使用softmax将这个‘得分’向量变成一个概率分布,将其结果作为权重与对应的hidden state做加权求和,将得到的结果与当前时刻decoder的hidden state 相加,作为下一个decoder hidden layer的输入。


